PandA: Unsupervised Learning of Parts and Appearances in the Feature Maps of GANs
James Oldfield1, Christos Tzelepis1, Yannis Panagakis2, Mihalis A Nicolaou3, Ioannis Patras1 1Queen Mary University of London, 2University of Athens, 3The Cyprus InstituteInternational Conference on Learning Representations (ICLR), 2023.
Paper Code Poster Video [ICLR] Video [YT] Colab demo

We propose a separable factorization of a dataset of intermediate generator's feature maps, providing an intuitive separation into representations of an images' parts and appearances. We achieve this through a semi-nonnegative decomposition of the feature maps—formulating and solving an appropriate constrained optimisation problem. Intuitively, the parts factors control the spatial regions at which the appearance factors are present, through their multiplicative interactions. Thus, the parts factors function similarly to semantic masks, but rather are learnt jointly, and in an entirely unsupervised manner.
Abstract
Recent advances in the understanding of Generative Adversarial Networks (GANs) have led to remarkable progress in visual editing and synthesis tasks, capitalizing on the rich semantics that are embedded in the latent spaces of pre-trained GANs. However, existing methods are often tailored to specific GAN architectures and are limited to either discovering global semantic directions that do not facilitate localized control, or require some form of supervision through manually provided regions or segmentation masks. In this light, we present an architecture-agnostic approach that jointly discovers factors representing spatial parts and their appearances in an entirely unsupervised fashion. These factors are obtained by applying a semi-nonnegative tensor factorization on the feature maps, which in turn enables context-aware local image editing with pixel-level control. In addition, we show that the discovered appearance factors correspond to saliency maps that localize concepts of interest, without using any labels. Experiments on a wide range of GAN architectures and datasets show that, in comparison to the state of the art, our method is far more efficient in terms of training time and, most importantly, provides much more accurate localized control.
Results
Local image editing
One can use the learnt appearance factors of interest to edit an image at the learnt target parts. This facilitates local image editing in a way that provides much more precise, pixel-level control over the SOTA.
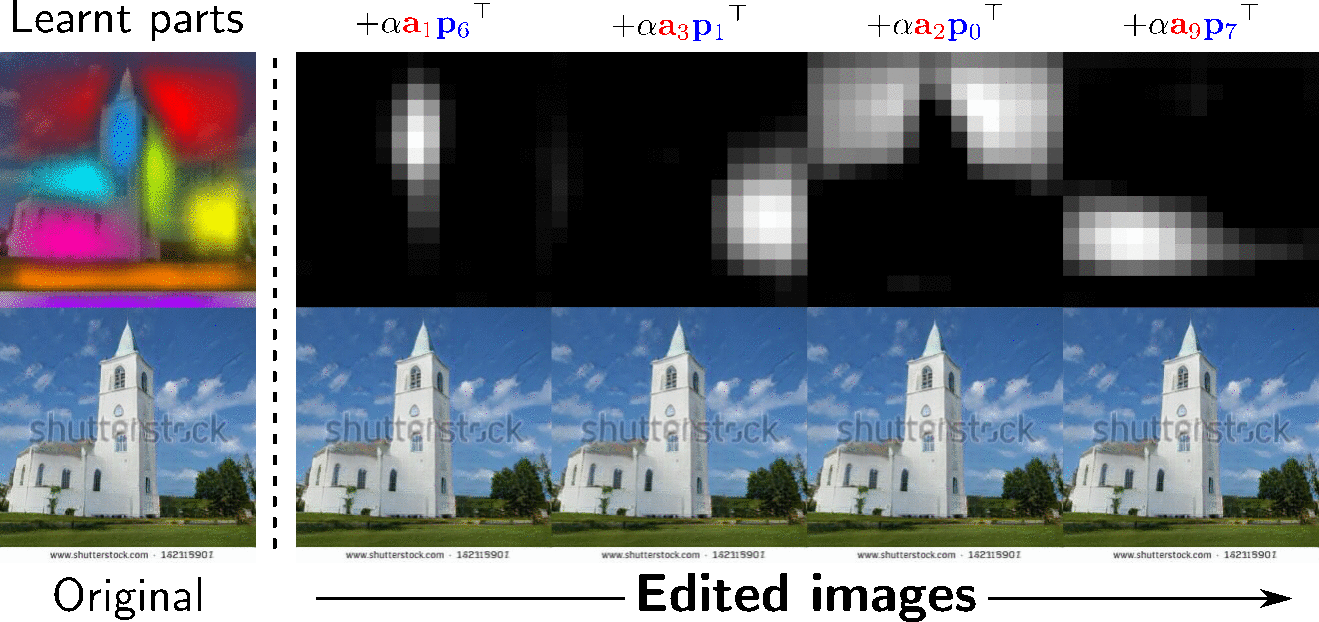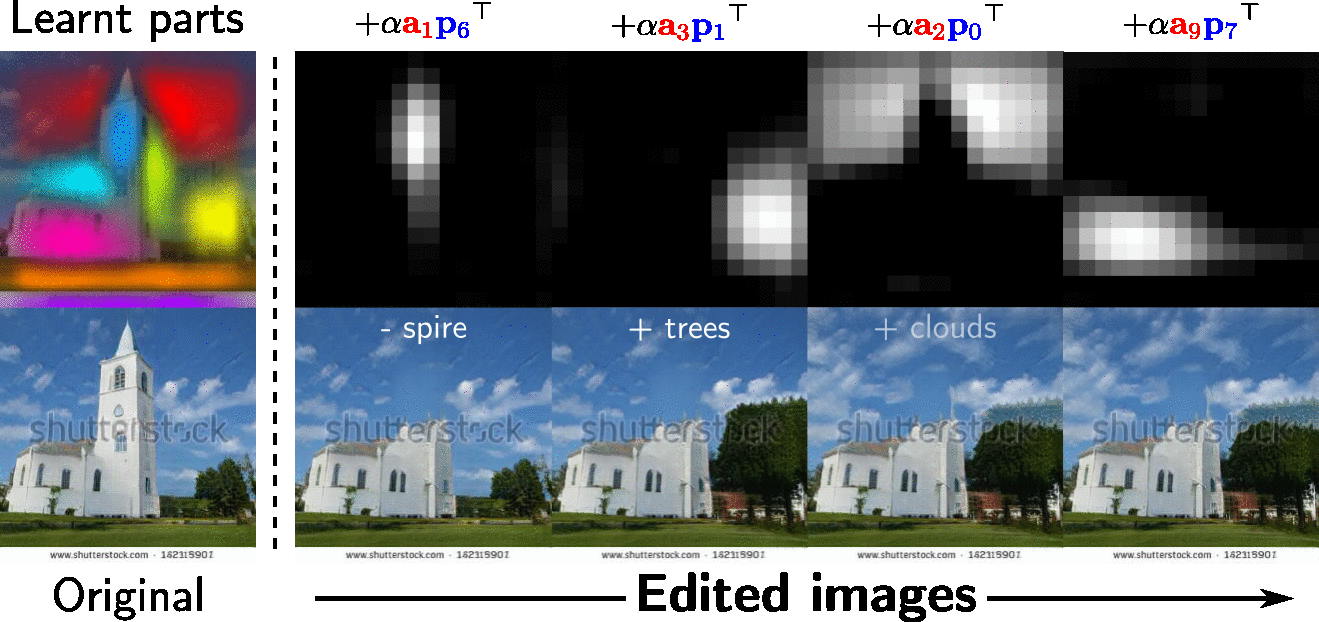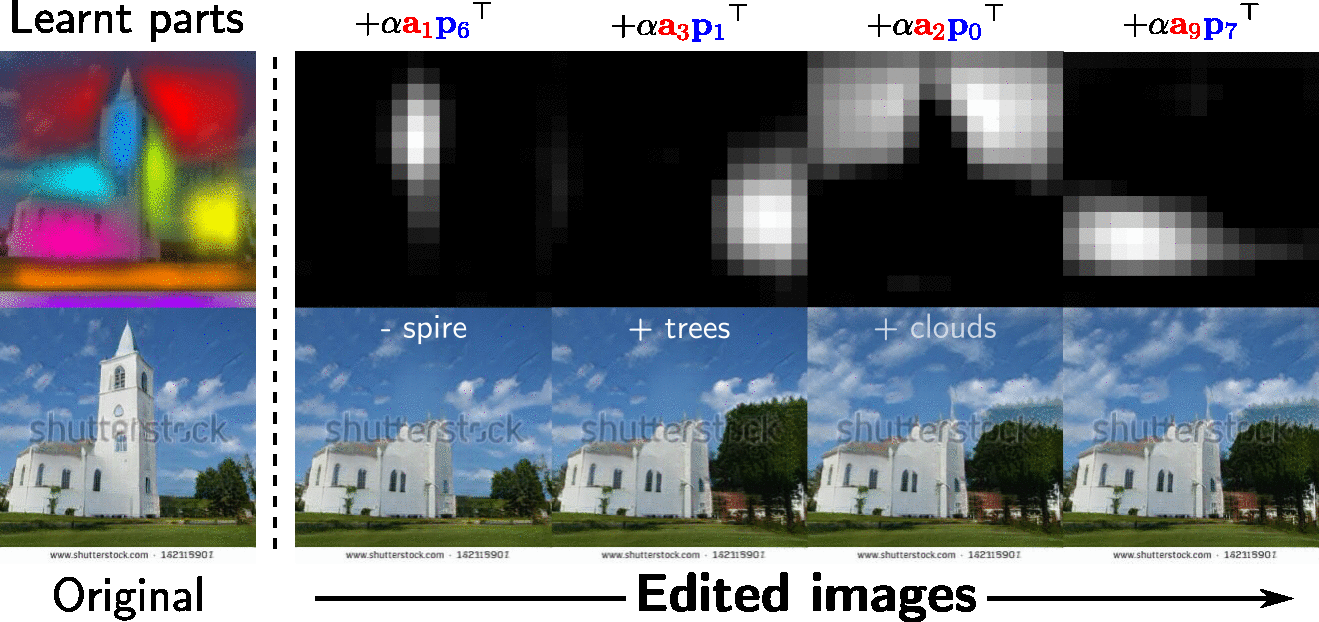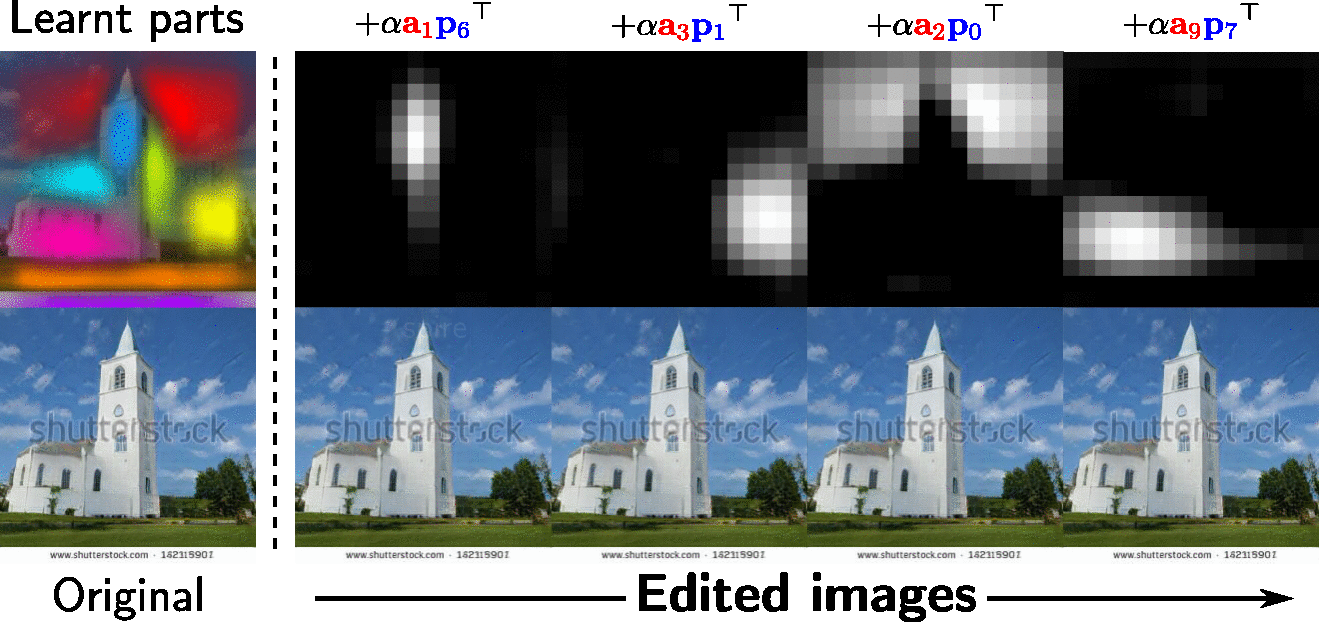
Demo
Part removal
The proposed method discovers generic high-level concepts (such as "background") in all 3 StyleGANs, ProgressiveGAN, and BigGAN, in an entirely unsupervised manner. Using this learnt representation for the "background" concept, we can straightforwardly remove objects of interest, in a context-aware manner:

Saliency maps
The learnt appearance vectors form a basis in which one can express the intermediate activations, encoding how much of each appearance vector is present at each spatial location in the feature maps. This localizes the learnt concepts of interest in the images, providing a pixel-level interpretation of the images' contents.
Furthermore, this provides a tool to visualize the concepts encoded by our learnt appearance vector, given whereabouts in the image the coordinates in the appearance basis are highest (for example, we easily identify a `skin' concept through its constant presence over the human faces).







BibTeX
If you find our work useful, please consider citing us:
@inproceedings{
oldfield2023panda,
title={PandA: Unsupervised Learning of Parts and Appearances in the Feature Maps of {GAN}s},
author={James Oldfield and Christos Tzelepis and Yannis Panagakis and Mihalis Nicolaou and Ioannis Patras},
booktitle={The Eleventh International Conference on Learning Representations },
year={2023},
url={https://openreview.net/forum?id=iUdSB2kK9GY}
}